|
gpufilter
GPU-Efficient Recursive Filtering and Summed-Area Tables
|
|
gpufilter
GPU-Efficient Recursive Filtering and Summed-Area Tables
|
Functions | |
| __global__ void | gpufilter::alg4_stage1 (float2 *g_transp_pybar, float2 *g_transp_ezhat) |
| Algorithm 4 stage 1. | |
| __global__ void | gpufilter::alg4_stage2_3 (float2 *g_transp_pybar, float2 *g_transp_ezhat) |
| Algorithm 4 stage 2 and 3 (fusioned) | |
| __global__ void | gpufilter::alg4_stage4 (float *g_transp_out, float2 *g_transp_py, float2 *g_transp_ez, float2 *g_pubar, float2 *g_evhat, int out_stride) |
| Algorithm 4 stage 4. | |
| __global__ void | gpufilter::alg4_stage5_6 (float2 *g_transp_pybar, float2 *g_transp_ezhat) |
| Algorithm 4 stage 5 and 6 (fusioned) | |
| __global__ void | gpufilter::alg4_stage7 (float *g_out, float2 *g_transp_py, float2 *g_transp_ez, int out_stride) |
| Algorithm 4 stage 7. | |
| __global__ void | gpufilter::alg5_stage1 (float *g_transp_pybar, float *g_transp_ezhat, float *g_ptucheck, float *g_etvtilde) |
| Algorithm 5 stage 1. | |
| __global__ void | gpufilter::alg5_stage2_3 (float *g_transp_pybar, float *g_transp_ezhat) |
| Algorithm 5 stage 2 and 3 (fusioned) | |
| __global__ void | gpufilter::alg5_stage4_5 (float *g_ptucheck, float *g_etvtilde, const float *g_transp_py, const float *g_transp_ez) |
| Algorithm 5 stage 4 and 5 (fusioned) | |
| __global__ void | gpufilter::alg5_stage6 (float *g_out, const float *g_transp_py, const float *g_transp_ez, const float *g_ptu, const float *g_etv) |
| Algorithm 5 stage 6. | |
| __global__ void | gpufilter::algSAT_stage1 (const float *g_in, float *g_ybar, float *g_vhat) |
| Algorithm SAT stage 1. | |
| __global__ void | gpufilter::algSAT_stage2 (float *g_ybar, float *g_ysum) |
| Algorithm SAT stage 2. | |
| __global__ void | gpufilter::algSAT_stage3 (const float *g_ysum, float *g_vhat) |
| Algorithm SAT stage 3. | |
| __global__ void | gpufilter::algSAT_stage4 (float *g_inout, const float *g_y, const float *g_v) |
| Algorithm SAT stage 4. | |
| __global__ void | gpufilter::algSAT_stage4 (float *g_out, const float *g_in, const float *g_y, const float *g_v) |
| Algorithm SAT stage 4 (not-in-place computation) | |
| __global__ void gpufilter::alg4_stage1 | ( | float2 * | g_transp_pybar, |
| float2 * | g_transp_ezhat | ||
| ) |
Algorithm 4 stage 1.
This function computes the algorithm stage 4.1 following:
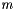 and
and 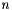 , compute and store the
, compute and store the 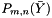 and
and 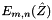 .
.| [out] | g_transp_pybar | All |
| [out] | g_transp_ezhat | All |
| __global__ void gpufilter::alg4_stage2_3 | ( | float2 * | g_transp_pybar, |
| float2 * | g_transp_ezhat | ||
| ) |
Algorithm 4 stage 2 and 3 (fusioned)
This function computes the algorithm stages 4.2 and 4.3 following:
, but in parallel for each , compute and store the 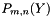 and using the previously computed ., but in parallel for each , compute and store the
and using the previously computed ., but in parallel for each , compute and store the 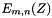 using the previously computed
using the previously computed 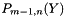 and .
and .| [in,out] | g_transp_pybar | All fixed to |
| [in,out] | g_transp_ezhat | All fixed to |
| __global__ void gpufilter::alg4_stage4 | ( | float * | g_transp_out, |
| float2 * | g_transp_py, | ||
| float2 * | g_transp_ez, | ||
| float2 * | g_pubar, | ||
| float2 * | g_evhat, | ||
| int | out_stride | ||
| ) |
Algorithm 4 stage 4.
This function computes the algorithm stage 4.4 following:
and , compute 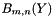 using the previously computed . Then compute and store the
using the previously computed . Then compute and store the 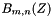 using the previously computed
using the previously computed 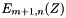 . Finally, compute and store both
. Finally, compute and store both 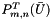 and
and 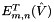 .
.| [out] | g_transp_out | The output 2D image transposed |
| [in] | g_transp_py | All |
| [in] | g_transp_ez | All |
| [out] | g_pubar | All |
| [out] | g_evhat | All |
| [in] | out_stride | Transposed output image stride |
| __global__ void gpufilter::alg4_stage5_6 | ( | float2 * | g_transp_pybar, |
| float2 * | g_transp_ezhat | ||
| ) |
Algorithm 4 stage 5 and 6 (fusioned)
This function computes algorithm stages 4.5 and 4.6 following:
, but in parallel for each , compute and store the 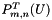 from ., but in parallel for each , compute and store each
from ., but in parallel for each , compute and store each 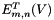 using the previously computed
using the previously computed 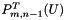 and .
and .| [in,out] | g_transp_pybar | All fixed to |
| [in,out] | g_transp_ezhat | All fixed to |
| __global__ void gpufilter::alg4_stage7 | ( | float * | g_out, |
| float2 * | g_transp_py, | ||
| float2 * | g_transp_ez, | ||
| int | out_stride | ||
| ) |
Algorithm 4 stage 7.
This function computes the algorithm stage 4.7 following:
and , compute 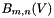 using the previously computed
using the previously computed 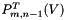 and . Then compute and store the
and . Then compute and store the 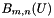 using the previously computed
using the previously computed 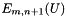 .
.| [out] | g_out | The output 2D image |
| [in] | g_transp_py | All |
| [in] | g_transp_ez | All |
| [in] | out_stride | Output image stride |
| __global__ void gpufilter::alg5_stage1 | ( | float * | g_transp_pybar, |
| float * | g_transp_ezhat, | ||
| float * | g_ptucheck, | ||
| float * | g_etvtilde | ||
| ) |
Algorithm 5 stage 1.
This function computes the algorithm stage 5.1 following:
and , compute and store each , , 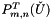 , and
, and 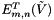 .
.| [out] | g_transp_pybar | All |
| [out] | g_transp_ezhat | All |
| [out] | g_ptucheck | All |
| [out] | g_etvtilde | All |
| __global__ void gpufilter::alg5_stage2_3 | ( | float * | g_transp_pybar, |
| float * | g_transp_ezhat | ||
| ) |
Algorithm 5 stage 2 and 3 (fusioned)
This function computes the algorithm stages 5.2 and 5.3 following:
, sequentially for each , compute and store the and using the previously computed .with simple kernel fusioned (going thorough global memory):
, sequentially for each , compute and store using the previously computed and 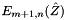 .
.| [in,out] | g_transp_pybar | All fixed to |
| [in,out] | g_transp_ezhat | All fixed to |
| __global__ void gpufilter::alg5_stage4_5 | ( | float * | g_ptucheck, |
| float * | g_etvtilde, | ||
| const float * | g_transp_py, | ||
| const float * | g_transp_ez | ||
| ) |
Algorithm 5 stage 4 and 5 (fusioned)
This function computes the algorithm stages 5.4 and 5.5 following:
, sequentially for each , compute and store and using the previously computed , , and .with simple kernel fusioned (going thorough global memory):
, sequentially for each , compute and store and using the previously computed , , , and .| [in,out] | g_ptucheck | All fixed to |
| [in,out] | g_etvtilde | All fixed to 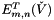 |
| [in] | g_transp_py | All |
| [in] | g_transp_ez | All |
| __global__ void gpufilter::alg5_stage6 | ( | float * | g_out, |
| const float * | g_transp_py, | ||
| const float * | g_transp_ez, | ||
| const float * | g_ptu, | ||
| const float * | g_etv | ||
| ) |
Algorithm 5 stage 6.
This function computes the algorithm stage 5.6 following:
and , compute one after the other , , , and and using the previously computed , , , and 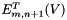 . Store .
. Store .| [out] | g_out | The output 2D image |
| [in] | g_transp_py | All |
| [in] | g_transp_ez | All |
| [in] | g_ptu | All |
| [in] | g_etv | All |
| __global__ void gpufilter::algSAT_stage1 | ( | const float * | g_in, |
| float * | g_ybar, | ||
| float * | g_vhat | ||
| ) |
Algorithm SAT stage 1.
This function computes the algorithm stage S.1 following:
In parallel for all and , compute and store the and 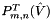 .
.
| [in] | g_in | Input image |
| [out] | g_ybar | All |
| [out] | g_vhat | All |
| __global__ void gpufilter::algSAT_stage2 | ( | float * | g_ybar, |
| float * | g_ysum | ||
| ) |
Algorithm SAT stage 2.
This function computes the algorithm stage S.2 following:
Sequentially for each , but in parallel for each , compute and store the and using the previously computed . Compute and store 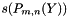 .
.
| [in,out] | g_ybar | All fixed to |
| [out] | g_ysum | All |
| __global__ void gpufilter::algSAT_stage3 | ( | const float * | g_ysum, |
| float * | g_vhat | ||
| ) |
Algorithm SAT stage 3.
This function computes the algorithm stage S.3 following:
Sequentially for each , but in parallel for each , compute and store the 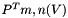 using the previously computed , and .
using the previously computed , and .
| [in] | g_ysum | All |
| [in,out] | g_vhat | All fixed to 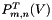 |
| __global__ void gpufilter::algSAT_stage4 | ( | float * | g_inout, |
| const float * | g_y, | ||
| const float * | g_v | ||
| ) |
Algorithm SAT stage 4.
This function computes the algorithm stage S.4 following:
In parallel for all and , compute then compute and store and using the previously computed and .
| [in,out] | g_inout | The input and output image |
| [in] | g_y | All |
| [in] | g_v | All |
| __global__ void gpufilter::algSAT_stage4 | ( | float * | g_out, |
| const float * | g_in, | ||
| const float * | g_y, | ||
| const float * | g_v | ||
| ) |
Algorithm SAT stage 4 (not-in-place computation)
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| [out] | g_out | The output image |
| [in] | g_in | The input image |
| [in] | g_y | All |
| [in] | g_v | All |
 1.7.5.1
1.7.5.1 
